深度拆解:DeepSeek首轮融资背后的成本结构与战略抉择
2024年的梁文峰意气风发。彼时DeepSeek高举开源大旗,幻方量化年利润数十亿,账上趴着充足弹药,融资二字从未出现在他的议事日程。那时的判断很朴素:AI烧钱速度再快,也快不过幻方的印钞能力。
这个判断在2025年末被打破了。
算力成本正在吞噬一切
大模型训练的账本正在改写。2023年训练GPT-4的投入约为一亿美元,到2025年,GPT-5.5的单次训练成本已突破数亿美元量级。算力采购价格不降反升,H100/H200显卡全球性短缺让每张卡的实际获取成本溢价超过50%。
DeepSeek面临的不是线性增长,而是指数级膨胀。V4训练费用、推理部署的GPU集群费用、日常迭代的人力成本,三项叠加构成了一座财务大山。幻方每年几十亿的利润听起来很多,但放在AI军备竞赛里,只是溅起一朵小水花。
竞品弹药充足度已不在同一量级
智谱2026年初港股上市,市值冲至4100亿港元。MiniMax同期登陆港股,市值2438亿港元。这两家入局时间与DeepSeek几乎同步,技术水平各有千秋。但上市后弹药量级的差距,已经拉开了。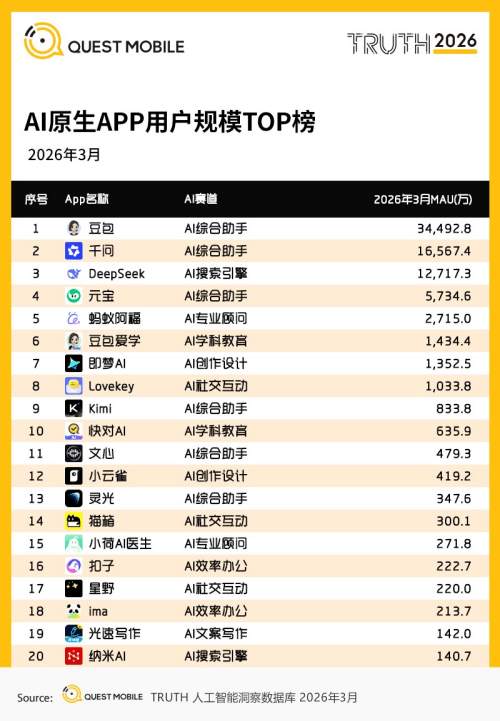
再看巨头动向。阿里宣布三年投入3800亿元建设AI基础设施,这个数字超过其过去十年累计投入。腾讯马化腾年初内部讲话明确表示,AI是唯一值得大力投入的业务线。字节豆包日均Token调用量突破120万亿,三个月翻倍,正在用规模优势构建成本护城河。
对比下来,幻方的几十亿利润显得有些单薄。
V4发布与融资消息同天出现的深层含义
OpenAI发布GPT-5.5当天,DeepSeek随即发布V4预览版。两家正面碰撞,业界瞬间嗅到了火药味。但细读这次发布背后的逻辑,融资消息的出现就有了完整的解释链条。
技术层面,V4在推理、数学、代码三项核心能力上提升显著,上下文窗口拉至百万token级别,与GPT-5.5同台竞技不落下风。开源策略让DeepSeek在全球开发者群体中建立了强大口碑,R1时代积累的品牌势能仍在。
但商业层面,开源模式的可持续性正在被重新审视。GPT-5.5走的是闭源收费路线,每一项能力都可以标价变现,形成“赚钱养研发、研发拉差距、差距带来更多收入”的正向飞轮。DeepSeek的开源策略能快速抢占市场、建立开发者生态,却在商业化闭环上存在结构性缺口。
V4很强,但下一代研发投入从哪里来?这个问题的紧迫性随着V4发布而上升。
阿里腾讯同时出现的战略逻辑
融资消息中还有一个细节:阿里与腾讯同时出现在绯闻名单里。这个组合本身就是信号。
阿里手握国内最大云基础设施,能解决DeepSeek的算力成本问题。腾讯拥有微信生态,在应用分发和商业化路径上具备优势。两者共同投资,既能提供资金,又能提供资源。
从投资方视角看,豆包月活3.45亿断层第一,千问1.66亿排第二,DeepSeek1.27亿排第三,元宝0.57亿排第四。阿里和腾讯都没能占据AI入口的榜首位置,投资DeepSeek是一种风险分散和赛道占位。
更深层看,DeepSeek是当前AI赛道少数还未站队的头部标的。拿下这张牌,意味着在未来的AI格局中多了一张底牌。错过这张牌,底牌就到了对手手里。这才是阿里腾讯同时出手的真正驱动力。
拿了钱的DeepSeek还是原来的DeepSeek吗
这是文章的结语,也是留给所有人的思考题。
梁文峰从“不融资”的宣言到接受外部资本的转变,折射的是AI赛道正在经历的深层次变化:当研发成本突破某个临界点后,技术理想主义必须与商业现实妥协。
DeepSeek的融资不是失败,是适应。关键在于拿到钱之后,这家公司能否在保持技术领先的同时,找到属于自己的商业闭环。这将决定它从“中国AI的希望”进化为“中国AI的胜者”,还是沦为另一个“大而不强”的故事。